It is my great pleasure to announce that I presented the work from my first year in Huawei at ICRA 2024, one of the top international robotics conferences, held in Yokohama.
The work is about a ful pipeline for allowing robots to play table-tennis by employing three different control strategies:
– Model-based
– Pure Reinforcement Learning
– Hybrid Reinforcement Learning
The goal of this work is also to show how to make Reinforcement Learning (RL) algorithms more sample efficient and safe by mixing learning with traditional physics and robot control strategies.

Each control strategy needs to identify the hitting parameters defined as a 10 dimesnional vector of 3D racket hitting position, 3D hitting velocity, 3D hitting orientation, hitting time.
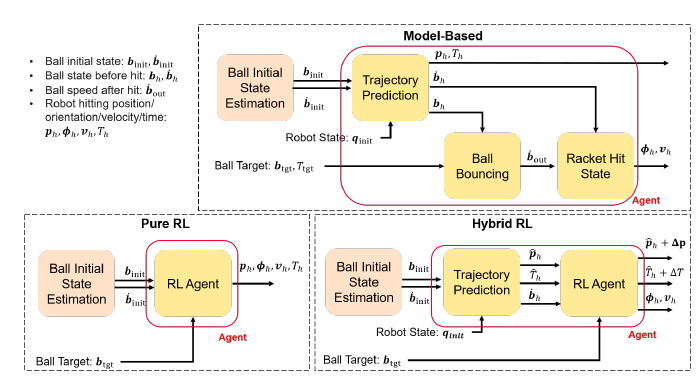
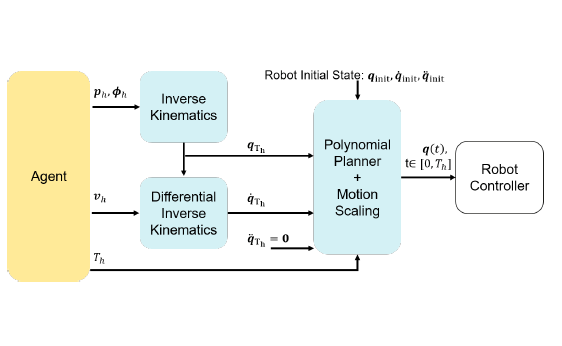
Once the hitting parameters are identified, a motion planner, with safety constraints on robot physicial limitations, is employed to guide the robot and execute the action. The benefit of using the motion planner is two-fold:
– allows inclusion of safety constraints;
– reduces the need for learning-based agents to learn full robot trajectories, making the agents more sample efficient and easier to train.
The Model-based agent pure relies on the ball-physics estimation to predict the ball trajectory, given an estimation of the ball initial state (ball position and velocity). Given the expected future states of the ball, the current robot state, and a target position for the ball to reach after being hit, it is possible to solve Oridnary Differential Equations (ODEs) and an optimization problem to identify the hitting parameters.
The Pure RL approach is a typical neural-network-based RL agent which is trained to output the hitting parameters given the intial ball state estimation.
The Hybrid RL mixes the Model-based and the Pure RL. In fact, given the inital ball state estimation, it predicts the hitting position, hitting time, and ball state at hitting time in the same way as the model-based approach. It then uses RL to learn a correction over the hitting position and time, and the full hitting velocity and orientation.
In both learning-based startegies, the RL setting is singl-step, given the use of the planner that takes the hitting parameters and directly execute the trajectory, without the need of having multiple learning steps per episode.

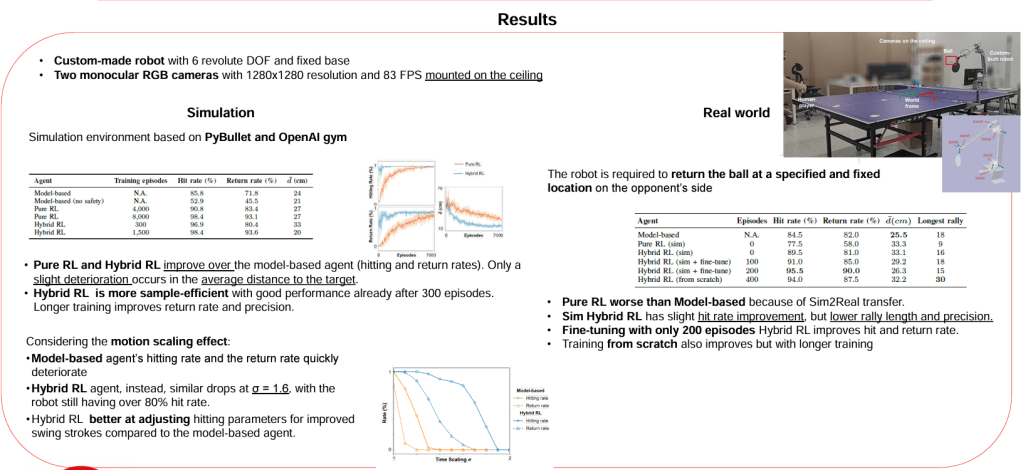
Our results show that learning-based startegies are able to compensate for modelling errors and thus outperform the Model-based one.
Most importantly, the use of some model-based features and of the motion planner make thr Hybrid RL the most sample efficient and the most effective agent bothnin simulation and in the real-world.