I am working on WeTalkRobots, my blog on Robotics and AI for robotics.
In WeTalkRobots I’ll go through some of the latest advancements in the field of robotics, analysing latest developments and summirizing research papers.
WeTalkRobots is both for more experienced researchers and engineers, but it also tries to reach out to less technical people through the podcast.
On the community side, Robotics and AI have been advancing very fast and many cool results have been shown.
As a researcher in the field, it’s hard to keep up with all the latest advancements. Also, common people may not be aware of the latest trends and might be curious to know how such results are achieved.
Personal Growth:
On the personal side, I have been curious on leveraging AI agents for web design. So I started with prompting Lovable to give me a frontend page. Then I add more functionalities with the help of LLMs like ChatGpt, Claude, Gemini.
The final goal is to have a pretty automated pipeline for me to load papers, make summary and podcast, and create the posts both for the website and for social platforms like Instagram, Twitter, Linkedin.
I have recently released AI Email, an AI agent based on Chatgpt which is capable of connecting to yorìur GMAIl account and read your emails. You can find the codes on GitHub. The Web interafce is built using Gradio.
How Does It Work?
The Agent can be prompted with authors or topics of interest, and with topics/authors that the user is not interested about. The architecture comprises 4 main elents: – Emailer class to establish the connection to GMAIL account and read emails. It is also responible for modifying the emails (e.g. set as read and move to trash). For each email message, it returns a dictionary containing the email author, the topic/title, the date of receipt, and the content of the email. – Author/Topic Checker: a ChatGPT-based LLM that checks whether or not the author and content of the email message are within those of interest for the user. – Interest Scorer: another LLM that given the list of authors/topics of interest scores the emial message giving a probability score between 0 and 1, with 1 representing the highest interest. – Summarizer: if the email message is considered relavent by the Interest Scorer, the full email content is passed to the summarizer in order for it to provide the main key points of the email.
The emails that are not considered of interest will be directly sent to trash.
In order for the user to be aware of the behaviour of the agents, the Gradio web app will return a list of both the discarded messages and those considered of interest, with the corresponding summary.
It is my great pleasure to announce that I presented the work from my first year in Huawei at ICRA 2024, one of the top international robotics conferences, held in Yokohama.
The work is about a ful pipeline for allowing robots to play table-tennis by employing three different control strategies: – Model-based – Pure Reinforcement Learning – Hybrid Reinforcement Learning
The goal of this work is also to show how to make Reinforcement Learning (RL) algorithms more sample efficient and safe by mixing learning with traditional physics and robot control strategies.
Our custom-made robot for table tennis
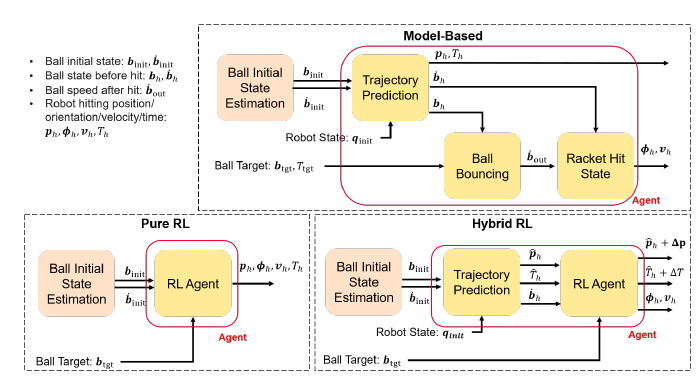
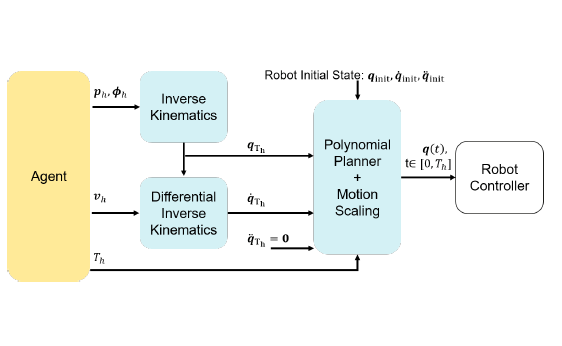
Each control strategy needs to identify the hitting parameters defined as a 10 dimesnional vector of 3D racket hitting position, 3D hitting velocity, 3D hitting orientation, hitting time.
The different strategies/agents
The control pipeline
Once the hitting parameters are identified, a motion planner, with safety constraints on robot physicial limitations, is employed to guide the robot and execute the action. The benefit of using the motion planner is two-fold: – allows inclusion of safety constraints; – reduces the need for learning-based agents to learn full robot trajectories, making the agents more sample efficient and easier to train.
The Model-based agent pure relies on the ball-physics estimation to predict the ball trajectory, given an estimation of the ball initial state (ball position and velocity). Given the expected future states of the ball, the current robot state, and a target position for the ball to reach after being hit, it is possible to solve Oridnary Differential Equations (ODEs) and an optimization problem to identify the hitting parameters.
The Pure RL approach is a typical neural-network-based RL agent which is trained to output the hitting parameters given the intial ball state estimation.
The Hybrid RL mixes the Model-based and the Pure RL. In fact, given the inital ball state estimation, it predicts the hitting position, hitting time, and ball state at hitting time in the same way as the model-based approach. It then uses RL to learn a correction over the hitting position and time, and the full hitting velocity and orientation.
In both learning-based startegies, the RL setting is singl-step, given the use of the planner that takes the hitting parameters and directly execute the trajectory, without the need of having multiple learning steps per episode.
Overview of the method to identify the hitting parameters with the different agents
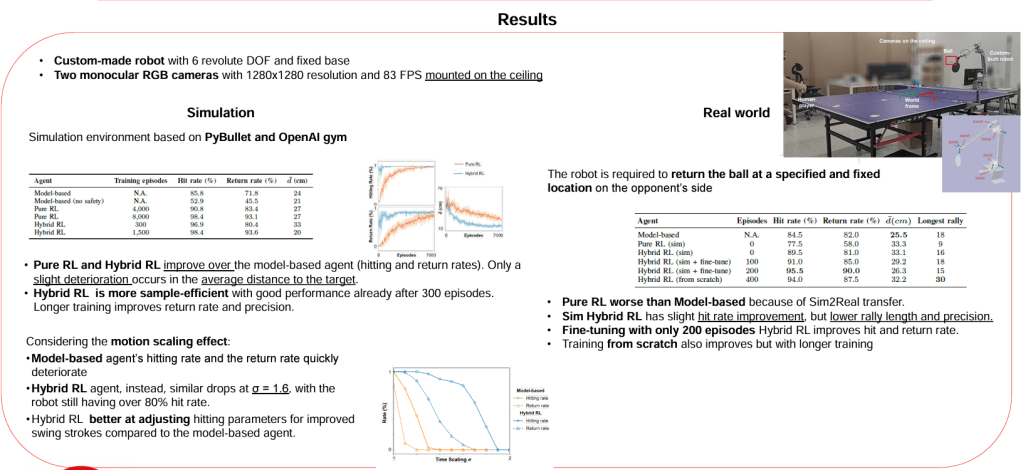
Our results show that learning-based startegies are able to compensate for modelling errors and thus outperform the Model-based one.
Most importantly, the use of some model-based features and of the motion planner make thr Hybrid RL the most sample efficient and the most effective agent bothnin simulation and in the real-world.
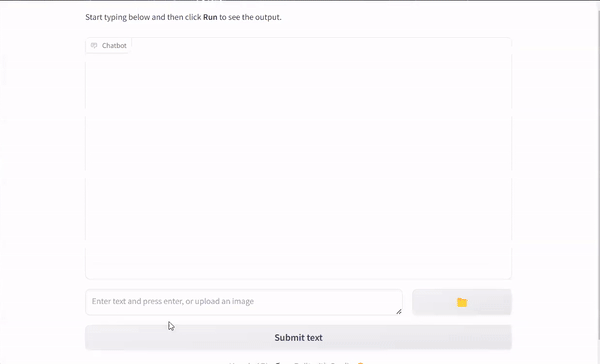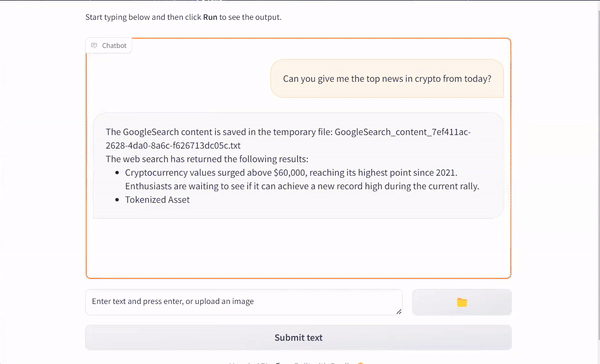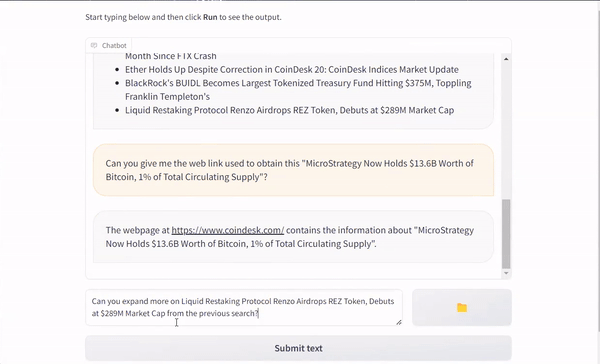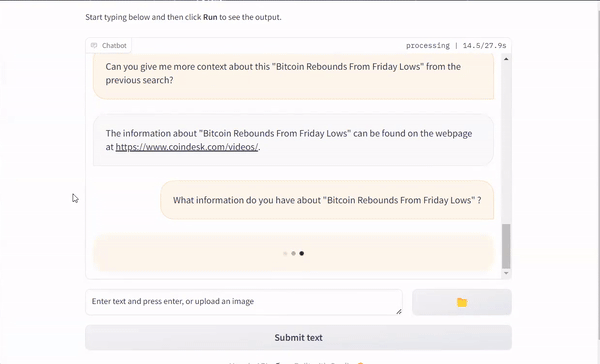
I have recently released SumMario, an AI agent based on Chatgpt which is capable of searching the internet for news, summarizing the news, summarizing Youtube video contents, and read txt, ppt, pdf files. You can find the codes on GitHub.
SumMario also acts as a personal assistant, being able to access its memory and keep conversating with the user about the stored data.
Here is a short demo of it for extracting daily news from the web and chatting about the obtained data.
SumMario example
How Does It Work?
SumMario relies on the lastest LLM technology like ChatGPT. It is a web-based agent, developed using Gradio, and LangChain for the integration of GPT agents.
SumMario is made of 3 different agents: SuperAgent, DataRetriever, and ConversationalAgent.
The SuperAgent isthe higher level AI agent responsible for managing the DataRetriever and the ConversationalAgent. Basically, it uses the other two agents as tools and, given specific prompts as system message and the user message, it is able to select which agent to choose to complete a task.
The ConversationalAgent is a basic Chatbot based on GPT. It’s purpose is to use directly LLM knowledge and reasoning skills to complete the user’s requirements. It has no access to external tools but only to its stored memory.
The DataRetriever, instead, is an AI agent with access to tools. The tools include GoogleWebSearch, WebPageSummarizer, VideoSummarizer, FileReader. Given the user’s query, the DataRetirever is thus able to select the proper tool and extract text from the source, it being a web page, a Youtube video, or a local file (pdf, ppt, word).
Each tool of the DataRetriever stores extracted text from the sources in a local temporary txt file. This file is accessible to the SuperAgent too, which, on instruction of the SuperAgent, can open the temporary txt file and help the DataRetriever complete the user’s defined task.
It is my great pleasure to announce that I was awarded the Excellent New Joiner award for the year 2023 at Huawei Hong Kong.
It was a honor for me to receive such an award from the company after my first year of joining it. I hope and I wish I will be able to keep contributing and give more for my personal and for the company’s success.
It is my great pleasure to announce that our latets paper has been publishe on IEEE Transaction on Instrumentation and Measurements (TIM).
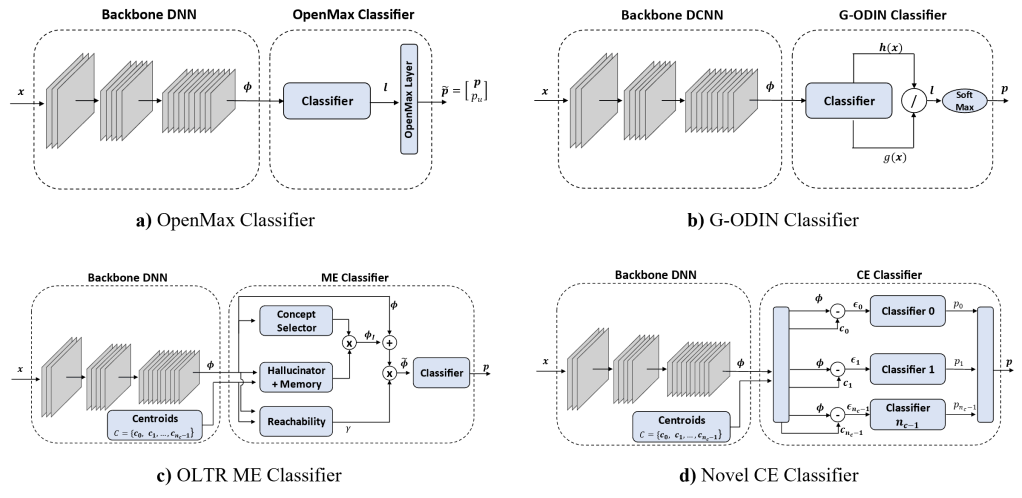
The work is about image classification for defect detection in LCD manufacturing, specifically open-set classification.
The models for open-set recognition and our novel proposed CE Classifier
Qualty assessment is of uttermost importance in industries like LCD manufacturing, in order to ensure products meet customer’s requirements and saving time and costs in the production.
Machine Learning for computer vision has had great advancements over the years and now there exist powerful models that are able to detect and segments objects in images. These models are, however, trained on large-scale open-source datasets, and do not perform well on smaller, industry-specific ones.
Additionally, these detectors are generally trained in closed-world assumptions, namely it is assumed that the classes used during training will be the same used in testing (during production).
However, this assumption is not always met, especially in the manufacturing industry, where new unknown defects may appear and be completely different from the known ones.
The goal of this work is to evaluate how state-of-the-art approaches for open-set classification perform on industry-specific datasets, and we additionally propose a novel model which is capable of properly classifying both the known and unknown classes, named Error Cluster Classifier.
In this work we compare:
Baseline Thresholded Softmax Classifier: which is a standard classifier model which identifies as unknonw classes those whose predicted probability is below a certain threshold.
OpenMax Classifier: which is similar to a standard classifier but with an additional head that models the probability distribution as a Weibull distribution.
G-ODIN: a model for identifying out-of-distribution data. G-ODIN takes an image classifier and splits the output into two functions, one to approximate the probability of the input of belonging to the in-distribution domain, and the other one predicting the joint probability of the input of belonging both to the in-distribution domain and to a known class.
Open Long-Tailed recognition (OLTR): which consists of a model to cluster features extracted from a backbone network. The extracted features are then fed into a Meta-Embedding classifier which predicts the final class probability. During training, the loss function tries to cluster the known class features appropriately.
Error Cluster Classifier: it is our proposed model that takes inspiration from OLTR. The main difference is in the classifier itself, which simply considers the distance of the backbone’s extracted features from learned class centroids to estimate the probability of the input of belonging to known classes. During training, the loss function tries to cluster the extracted features, such that features of the same class belong to the same cluster and are pushed away from the non-class clusters.
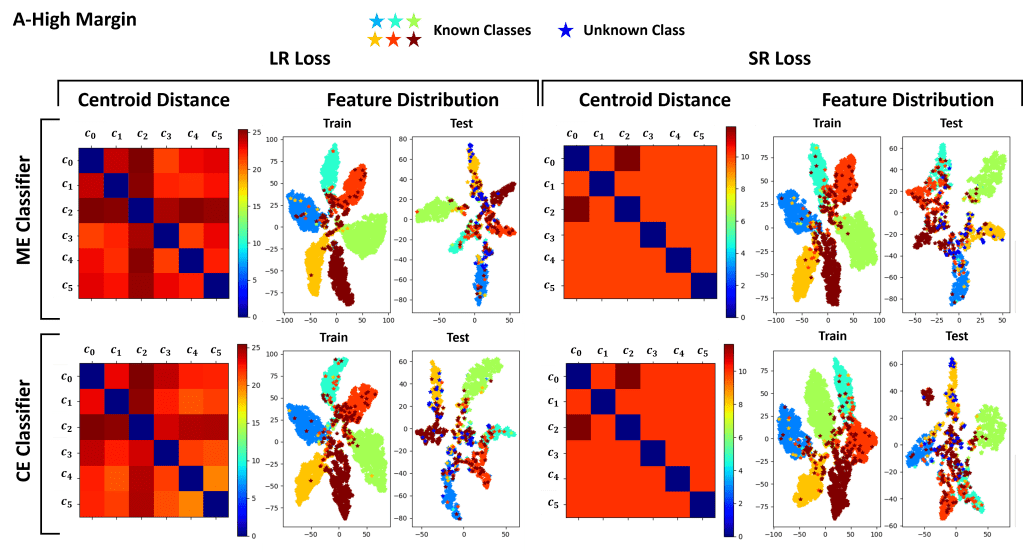
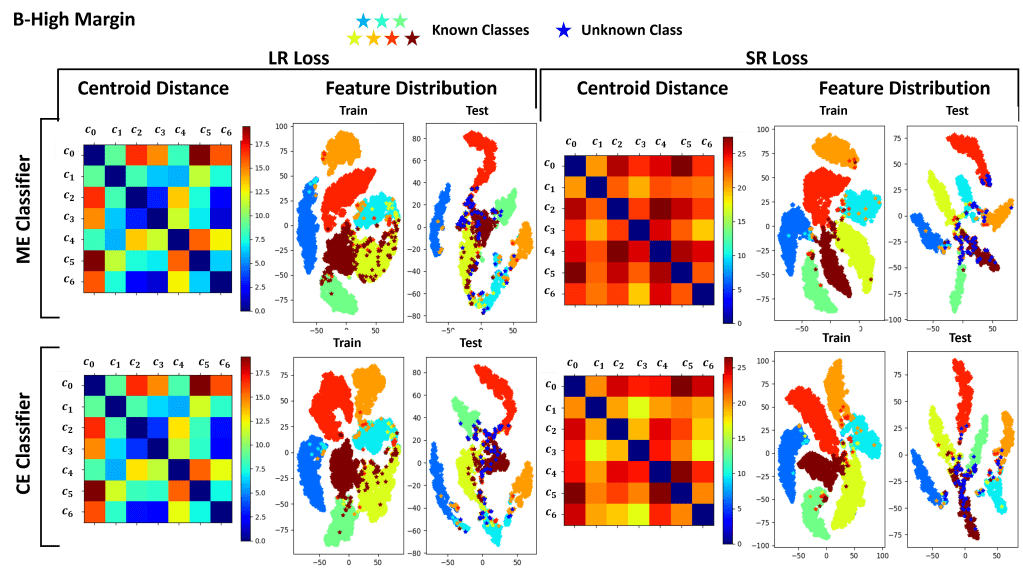
In this work we also propose a novel loss for clustering the features, named Strongly Repulsiv (SR) loss. Differently from the standard Low Repulsive (LR) clustering loss, the SR loss tries to cluster extracted features by forcing a given distribution.
The SR loss clustering
For a given class, the loss penalizes the model when the features are further than a certain radius from the class centroid. It also tries to push the centroids further away from each other, so that to ensure that features of the different classes can be properly slpit
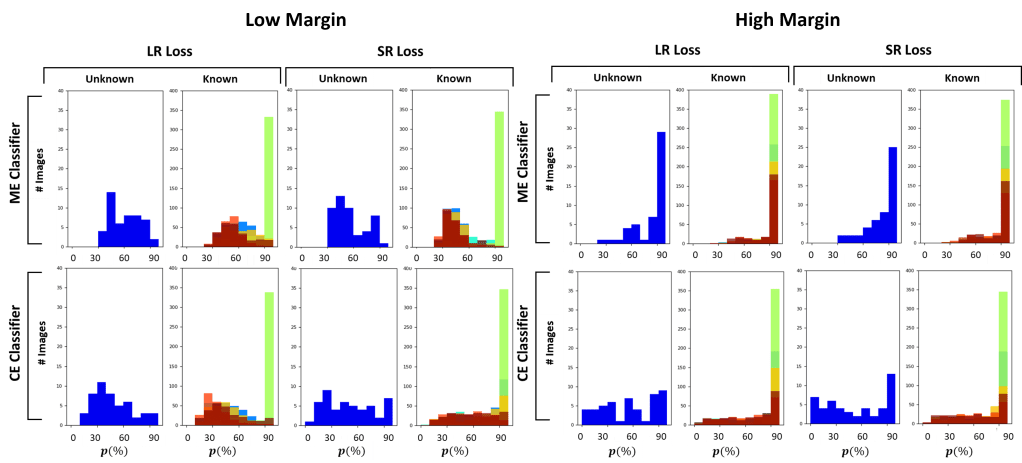
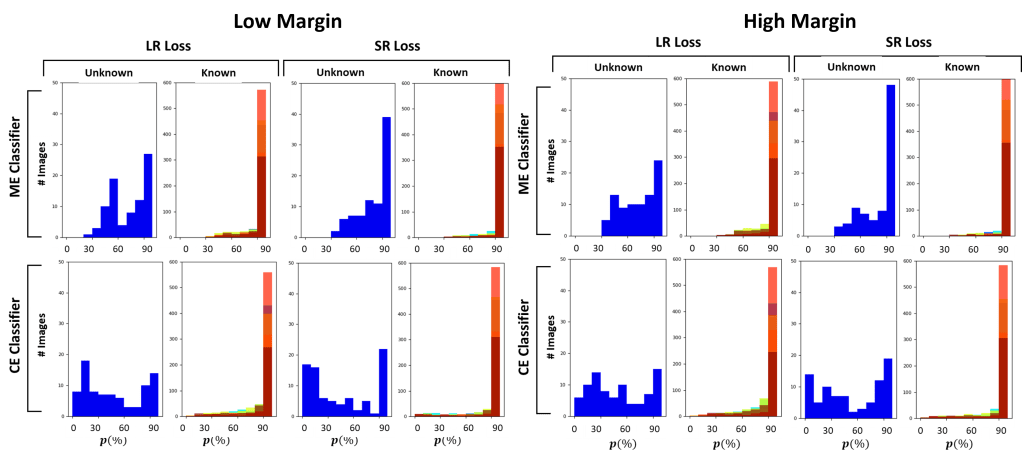
We tested the approaches on two different LCD datasets.
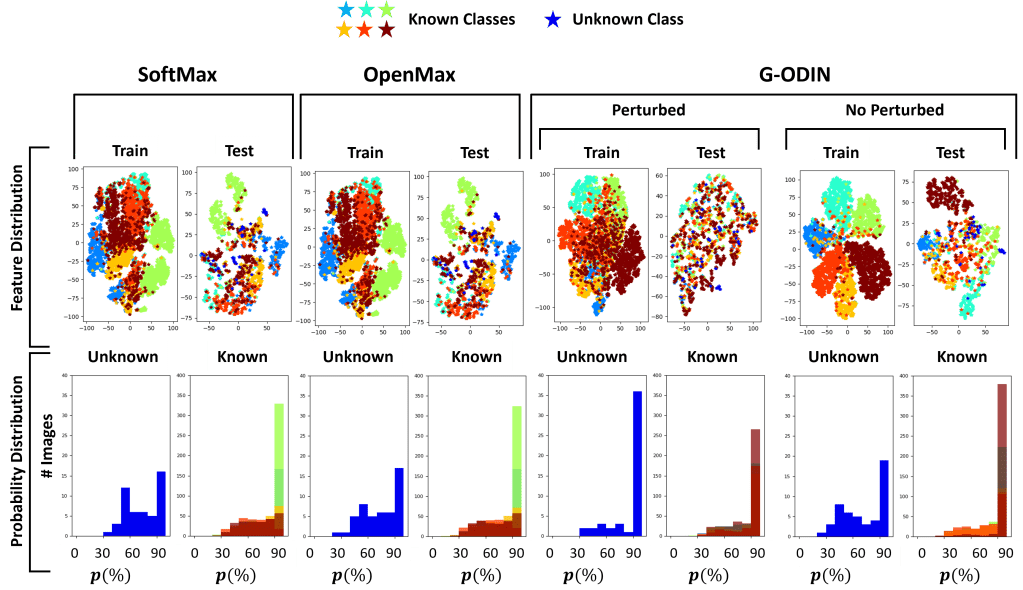
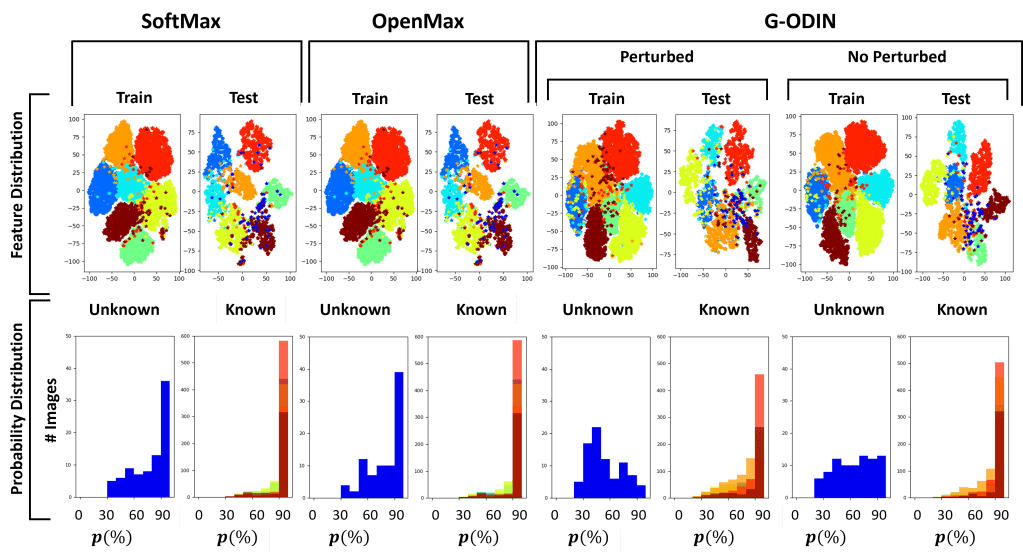
Feature and probability distribution on Dataset A
Feature and probability distribution on Dataset B
Feature distribution and centroid distance on Dataset A
Feature distribution and centroid distance on Dataset B
Probability distribution on Dataset A for OLTR and CE classifier.
Probability distribution on Dataset B for OLTR and CE classifier.
Classification accuracy for each model on the different datasets as a function of the classification threshold.
In conclusion, our work shows the difficulties of state-of-the-art approaches in dealing with unseen classes. From our experiments, it is evident that feature clustering approaches like OLTR and CE cClassifier perform generally better.
Overall, the proposed CE classifier is the one that perfromrs the best on both datasets, given its capability of predicting the input’s class by estimating the distance of the extracted features from the trained known class centroids.
Accepted for publication in IEEE Transaction in Automation Science and Engineering (T-ASE), 2022
Description:
Machine learning and Artificial Neural Networks (ANN) can be powerful tools to model complex systems like robots. In fileds like surgery, robots are very complex, and analytical models are hard to compute. Having an accurate model is, however, fundamental in order to ensure safety and precise motion, espeially becuase sensors can hardly be used in such scenarios.
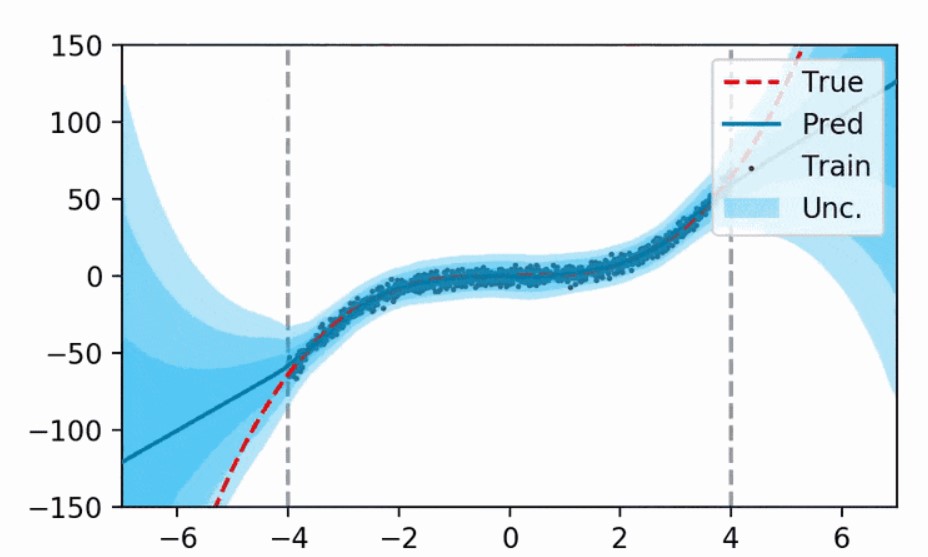
One major limitiation of ANN, is that they are deterministic, meaning that they only provide a “punctual” prediction, given an input. However, the models and the data have uncertainties themselves, and an estimation of these uncertainties could be beneficial to have an estimation of the confidence level of the model.
Probabilistic Neural Networks can solve this problem. Approaches like Bayesian Neural Networks (BNN) and Evidential Neural Networks (EvNN) allow having not only the model’s prediction, but also the setimation of the model’s uncertainty (epistemic undertainty) and data uncertainty (aleatoric uncertainty).
Example of uncertainty estimation from an EvNN model
In this work we propose the use of BNN and EvNN to model the forward kinematics of a surgical robot. The surgical instrument is mounted on top of a serial-link manipulator in a macro-micro manipulator setup.
For the control of the overall system, to perform a surgical task, we employ Hierarchical Quadratic Programming (HQP) in order to exploit the hyper-redundancy of the system and impose two prioritized tasks: 1) ensuring fulcrum effect at the insertion point location, also known as Remote Centr of Motion (RCM) constraint; 2) tracking a given path, to simulate a tumor resection task.
Additioanlly, we include a lower level task solved by means of a Sequential Qudaratic Programming (SQP) probelm in order to minimize the model’s uncertainty during operation and ensure the robot perfroms the task with the highest confidence possible.
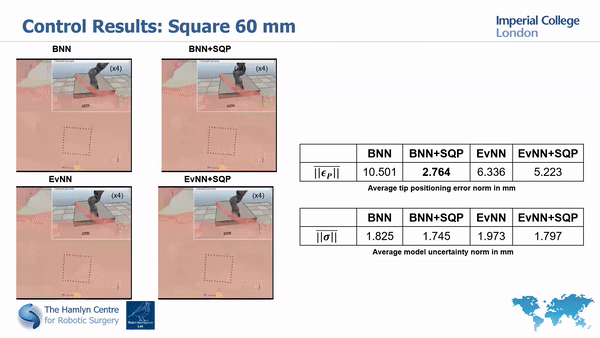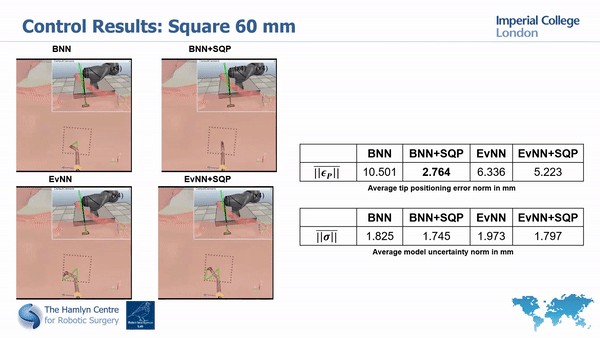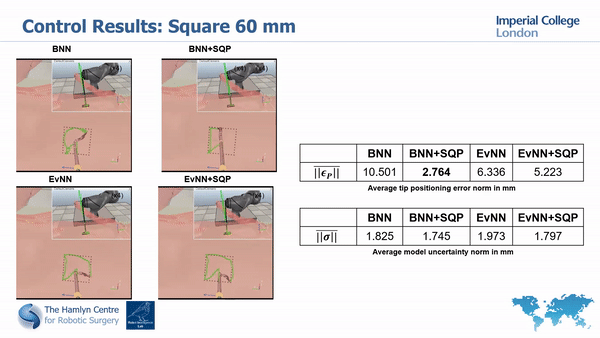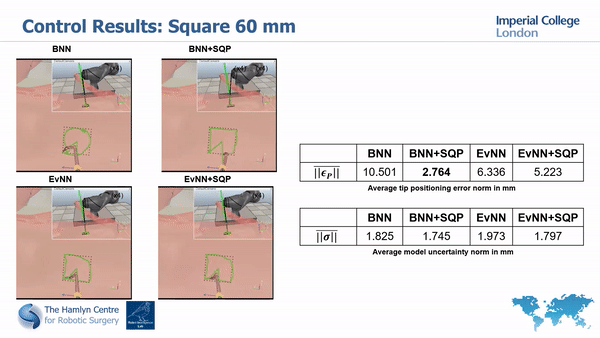
Simualtion results
Real world results
Our simulation and real world tests show the importance of minimizing model’s unceratinties in order to guarantee safety and improve task execution.
In fact, without the uncertainty minimization, the robot doesn’t manage to accurately track the desired paths; much higher accuracy is instead achieved with our proposed approach.
It is my great pleasure to announce that I presented two of my PhD works at IROS 2022, one of the top international robotics conferences, held in Kyoto.
The two works are those described in :
Augmented Neural Network for Full Robot Kinematic Modelling in SE(3), published in IEEE Robotics and Automation Letters (RAL), about including differential relationships during model learning with Artificial Neural Networks for robot kinematics. You can check the brief summary here and the full paper here.
Optimization of Surgical Robotic Instrument Mounting in a Macro–Micro Manipulator Setup for Improving Task Execution, published in IEEE Transaction on Robotics (T-RO), about an optimization framework for identifying the optimal mounting connection between a serial-link robotic arm and a surgical robotic tool. You can check the summary here and the paper here.
I am here sharing the videos of my presentations during the conference.
Accepted for publication in IEEE Robotics and Automation Letters (RAL), 2022
Description:
Surgical robots are very complex systems, due to the requirements for miniaturization and high dexterity. This leads to highly articulated and complex designs to increase the system’s felxibility and dexterity, while the miniaturization requirement leads to the choice of non-traditional actuation systems like tendons.
A traditional serial-link robot
A tendon-driven robot
Differently from traditional serial-link manipulators, generally used in the manufacturing industry, tendon-driven robots do not have motors directly on the joints, but they are placed on the robot’s base and connected to the joints by means of wires (the tendons).
This setup causes a lot of complexities in the system due to high nonlinearities due to tendon friction, slack, tendon elongation, that, in turn, cause effects like backlash and hysteresis.
Hystereis is phenomenon that causes a system not to behave in the same way when moving in a direction or in the opposite one. Backlash occurs when a change in motion direction occurs and, despite commanding non-null velocities, the system lies in a deadzone and does not move. In tendon-driven system this is typically due to the tendon elongation and possible slack when motors change their direction of motion.
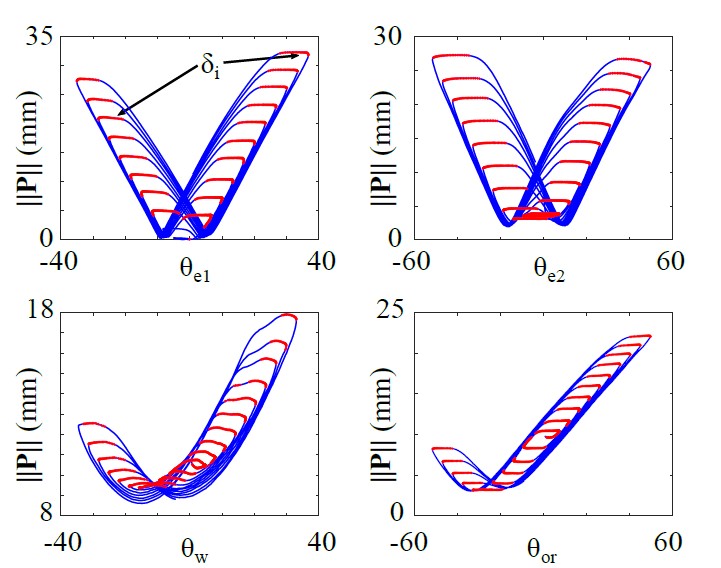
Example of backlash in a tendon-driven robot. When the motor values are within the read areas (deadzones), the tip position doesn’t change and the robot stands still.
Machine learning (ML) techniques have been very efficient in building complex robot models, especially for surgical robots that are very hard to model. These approaches, however, do not consider andy a priori knowledge of backlash and hysteresis and if and end-to-end black box model is used, the model should be able to inherently learn a compensation strategy. This makes the application of ML moelling tedious in surgical robots.
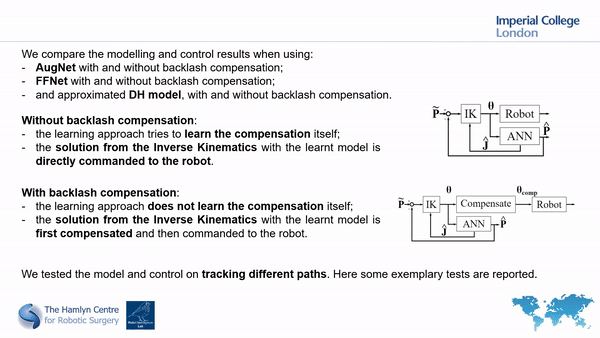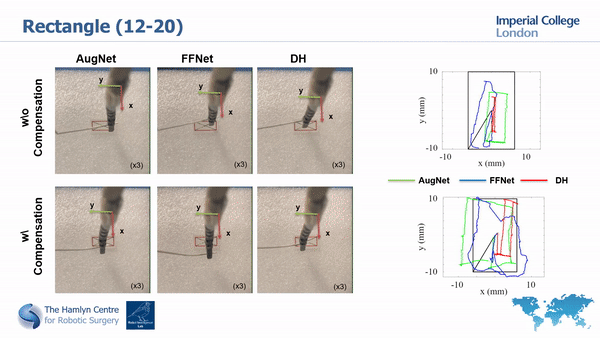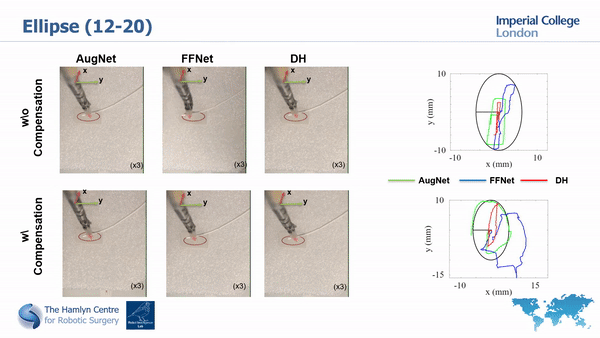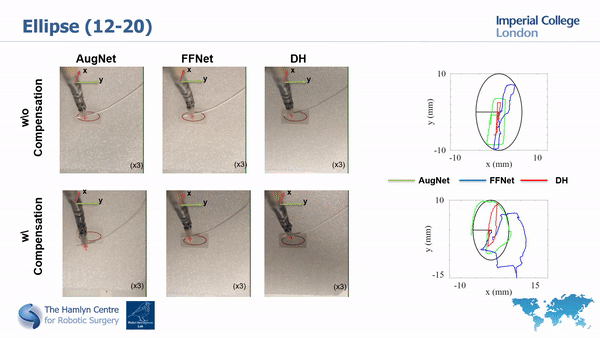
In this work we propose a backlash compensation technique and use Artificial Neural Networks to model the complexities of a tendon-driven surgical robot from the compensated values.
The a priori backlash compensation is used to reduce the nonlinearities in the system and make it easier to learn a more accurate and simpler robot model.
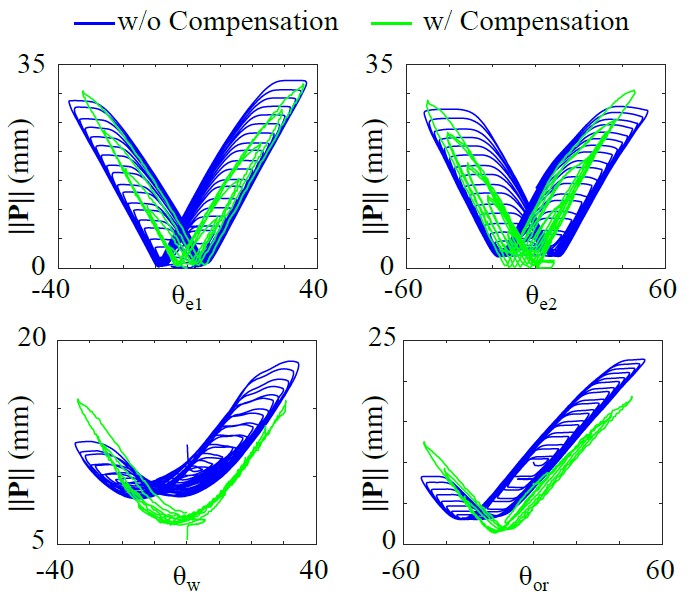
Results for our proposed backlash compensation
With our backlash compensation approach we could reduce the occurrence of deadzones by 89%, thus limiting the stationary motion of the robot.
We then employ two different approaches to model our robot (a traditional ANN and our proposed AugNet, which incorporates differential relationships during training) and performed path tracking tests with and without the backlash compensation.
The path tracking results
Our results show the importance of compansating for high nonlinearities before using ML approaches and that our compensation approach helps improving system’s tracking accuracy.