It is my great pleasure to announce that our latets paper has been publishe on IEEE Transaction on Instrumentation and Measurements (TIM).
The work is about image classification for defect detection in LCD manufacturing, specifically open-set classification.
Qualty assessment is of uttermost importance in industries like LCD manufacturing, in order to ensure products meet customer’s requirements and saving time and costs in the production.
Machine Learning for computer vision has had great advancements over the years and now there exist powerful models that are able to detect and segments objects in images. These models are, however, trained on large-scale open-source datasets, and do not perform well on smaller, industry-specific ones.
Additionally, these detectors are generally trained in closed-world assumptions, namely it is assumed that the classes used during training will be the same used in testing (during production).
However, this assumption is not always met, especially in the manufacturing industry, where new unknown defects may appear and be completely different from the known ones.
The goal of this work is to evaluate how state-of-the-art approaches for open-set classification perform on industry-specific datasets, and we additionally propose a novel model which is capable of properly classifying both the known and unknown classes, named Error Cluster Classifier.
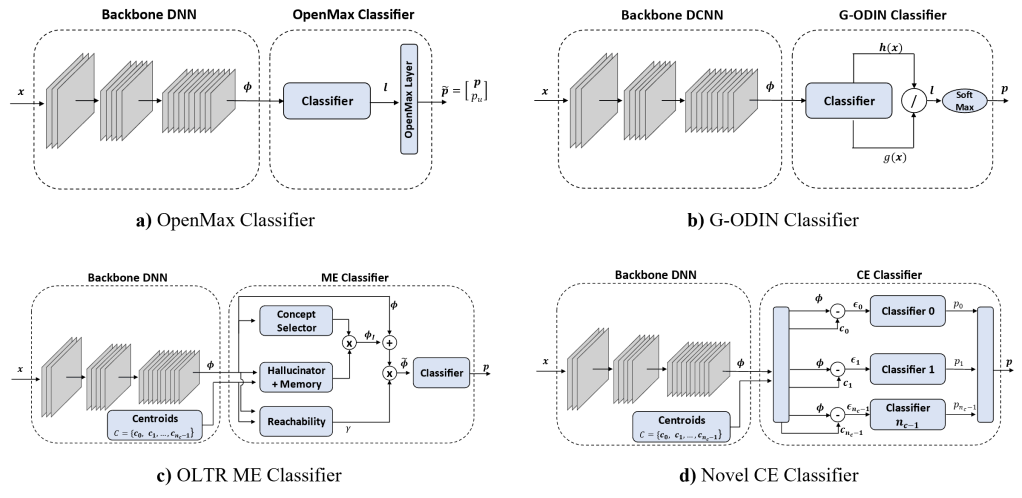
In this work we compare:
- Baseline Thresholded Softmax Classifier: which is a standard classifier model which identifies as unknonw classes those whose predicted probability is below a certain threshold.
- OpenMax Classifier: which is similar to a standard classifier but with an additional head that models the probability distribution as a Weibull distribution.
- G-ODIN: a model for identifying out-of-distribution data. G-ODIN takes an image classifier and splits the output into two functions, one to approximate the probability of the input of belonging to the in-distribution domain, and the other one predicting the joint probability of the input of belonging both to the in-distribution domain and to a known class.
- Open Long-Tailed recognition (OLTR): which consists of a model to cluster features extracted from a backbone network. The extracted features are then fed into a Meta-Embedding classifier which predicts the final class probability. During training, the loss function tries to cluster the known class features appropriately.
- Error Cluster Classifier: it is our proposed model that takes inspiration from OLTR. The main difference is in the classifier itself, which simply considers the distance of the backbone’s extracted features from learned class centroids to estimate the probability of the input of belonging to known classes. During training, the loss function tries to cluster the extracted features, such that features of the same class belong to the same cluster and are pushed away from the non-class clusters.
In this work we also propose a novel loss for clustering the features, named Strongly Repulsiv (SR) loss. Differently from the standard Low Repulsive (LR) clustering loss, the SR loss tries to cluster extracted features by forcing a given distribution.

For a given class, the loss penalizes the model when the features are further than a certain radius from the class centroid. It also tries to push the centroids further away from each other, so that to ensure that features of the different classes can be properly slpit
We tested the approaches on two different LCD datasets.
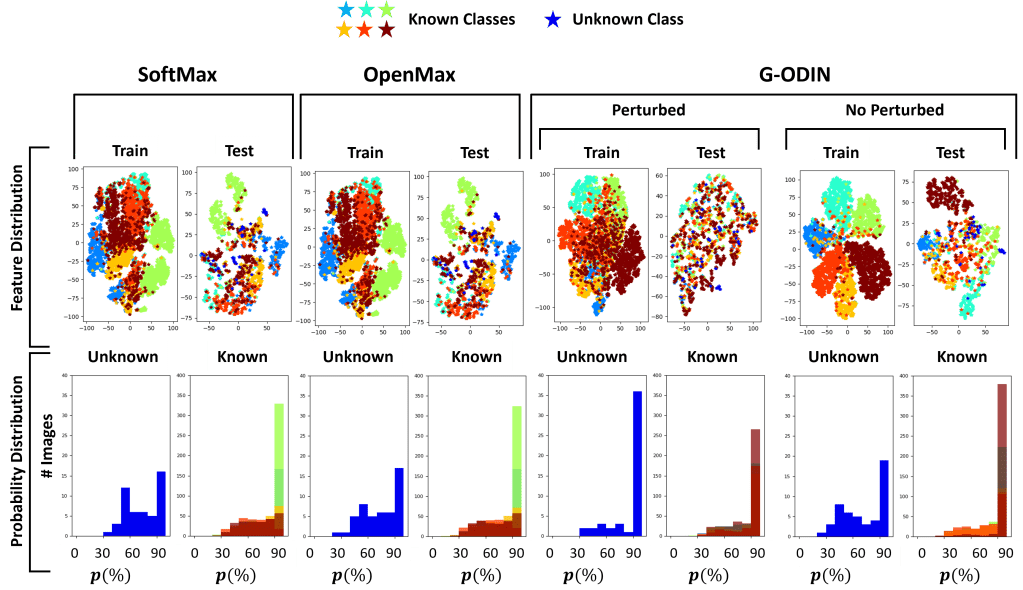
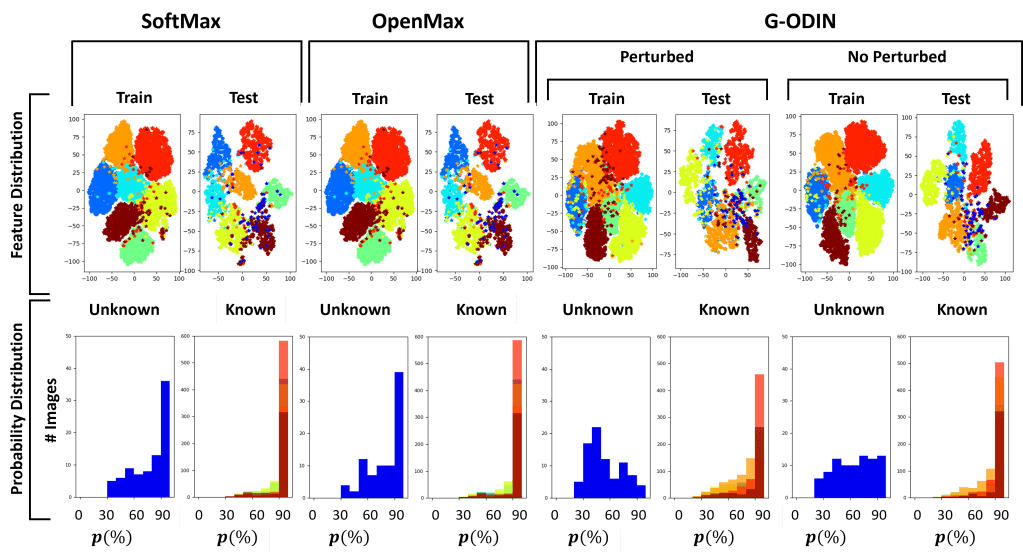
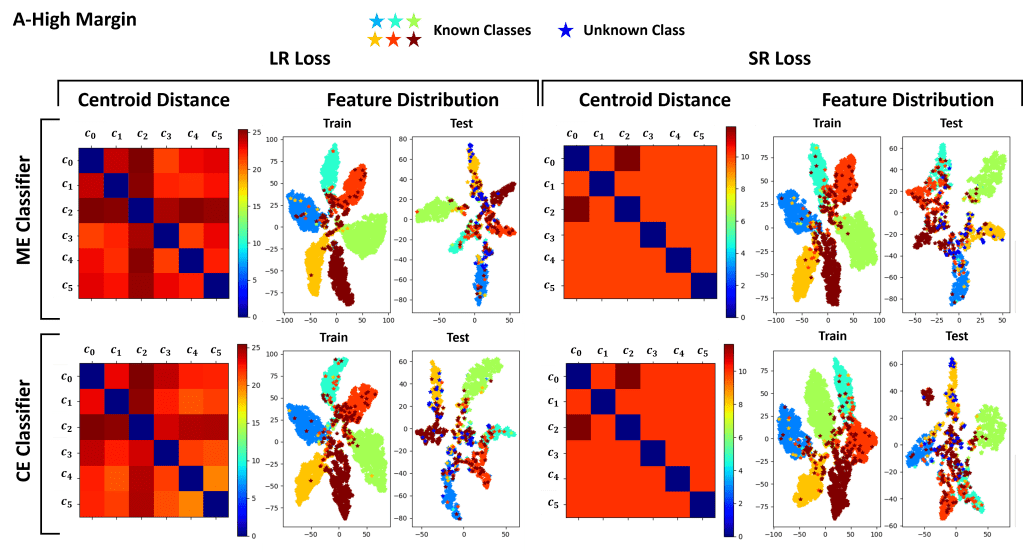
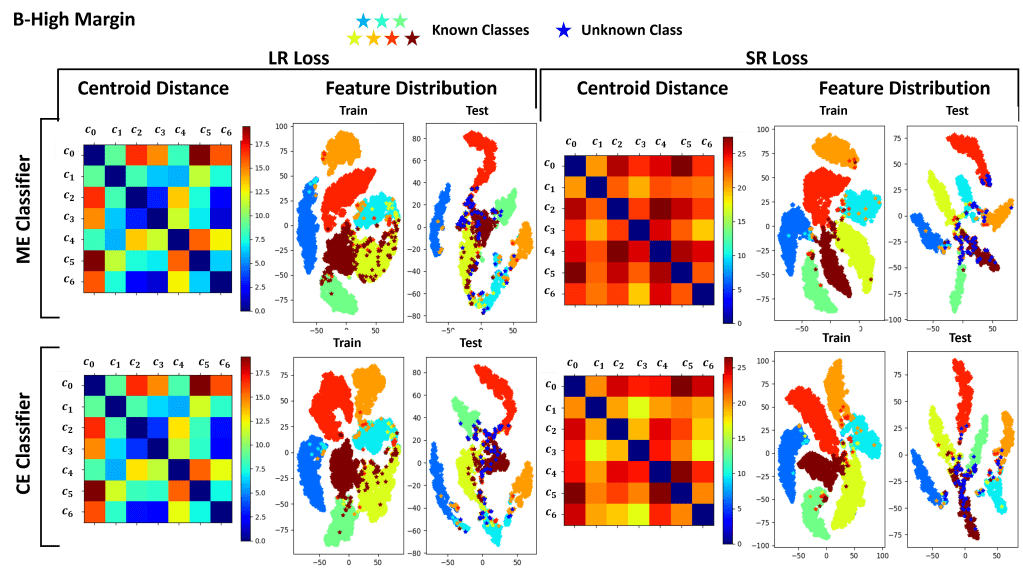
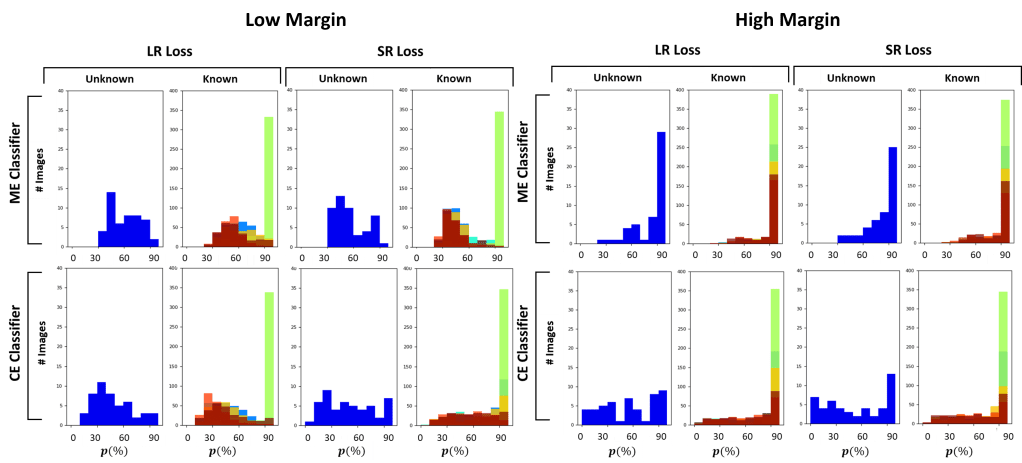
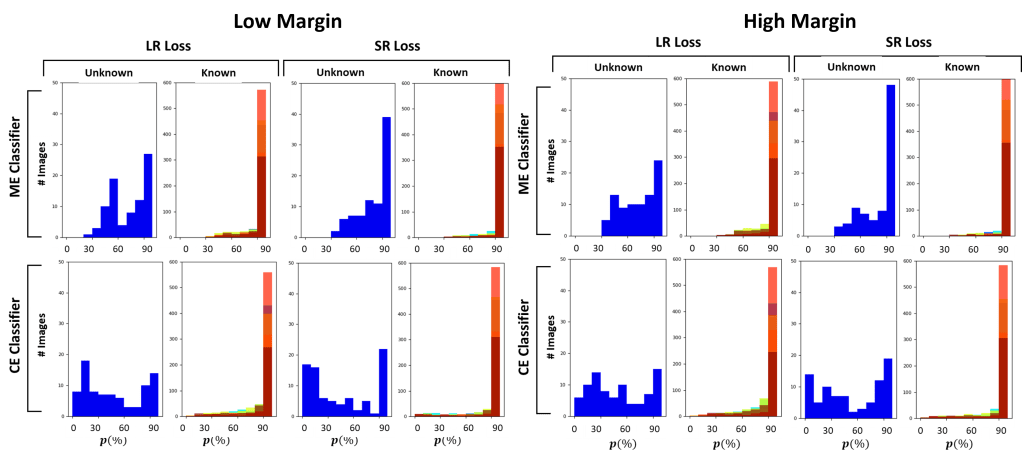

In conclusion, our work shows the difficulties of state-of-the-art approaches in dealing with unseen classes. From our experiments, it is evident that feature clustering approaches like OLTR and CE cClassifier perform generally better.
Overall, the proposed CE classifier is the one that perfromrs the best on both datasets, given its capability of predicting the input’s class by estimating the distance of the extracted features from the trained known class centroids.
